FLAC Decoder Benchmarking on ARM
The purpose of this project was to design the HW/SW architecture of an innovative audio decoder for extremely high quality music. The main target was to be able to decode, and eventually to stream, several channels of music in lossless FLAC format with bit rate of several Mb/s. Just to have an idea of the target quality and complexity of such design is sufficient to remember that a standard MP3 audio file has a typical bit rate of 128 kb/s for a dual channel stereo, so well over 10X less than our objective.
We started by developing a baseline software solution for the FLAC decoder without the need of any hardware accelerators, then we decided to benchmark it on a typical baseline ARM architecture: ARM Cortex-A53 at 1.2Ghz in single-core configuration.
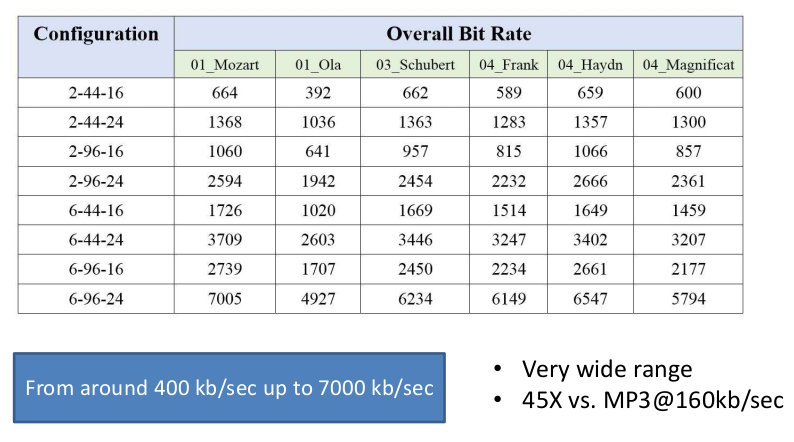
The FLAC format is a lossless compression which supports from 4 to 24 bits per sample, sampling rate up to 655 khz and up 8 channels. Since our focus was extremely high quality music we decided to test only the high end of the FLAC format, we chose some available recording with sampling rate up to 96Khz, 24 bits per sample and up to 6 channels (5+1 surround). In particular, the benchmark set consisted of 6 very high quality recording with average bit rate from around 400 kb/se up to 7 Mb/s as it is reported in the following image.
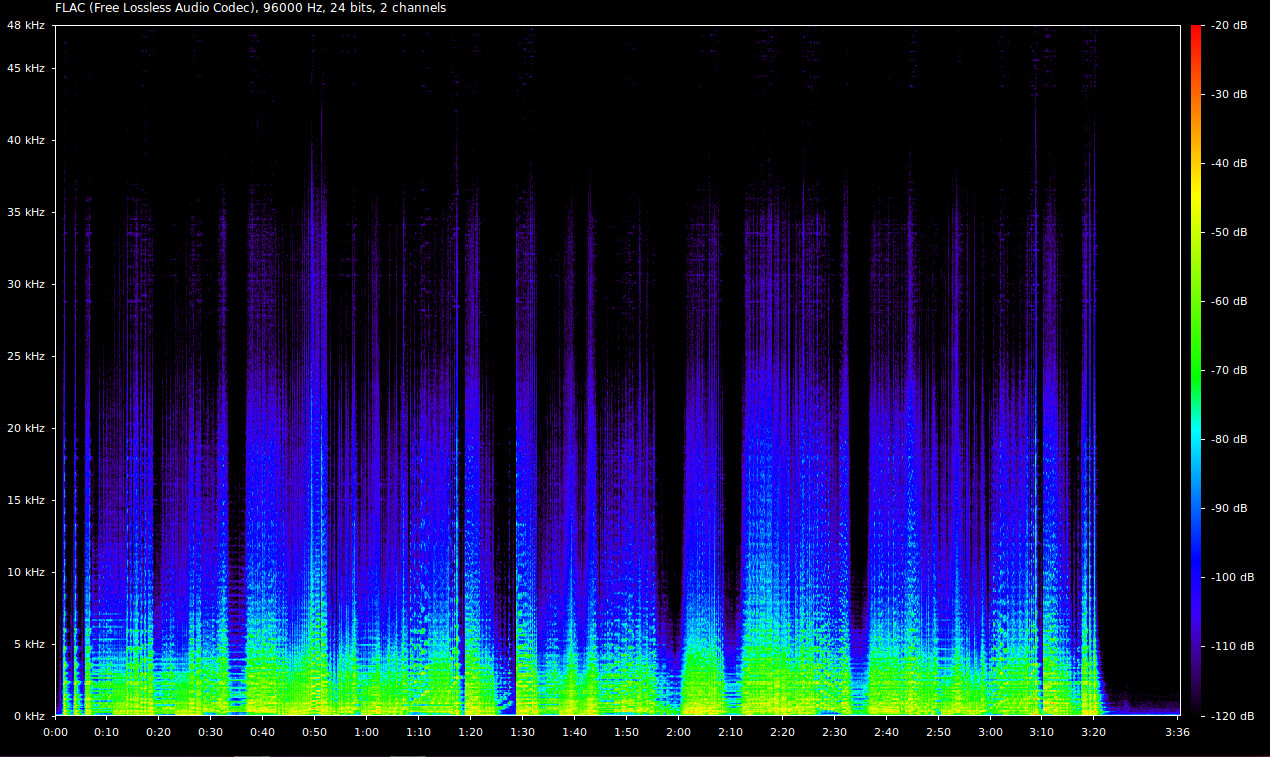
The average bit rates and their distributions were computed by analyzing the audiogram like the ones in the picture. As we can see the frequency range is quite large, from 0 up to 48 khz in these samples, well over the typical frequencies of standard audio recording - hence the denomination of extremely high quality music. While several configuration of the same recording were generated by taking such high quality recording (96Khz, 24 bits, 6 channels) first and down-sampling and re-encoding it with the right parameters.
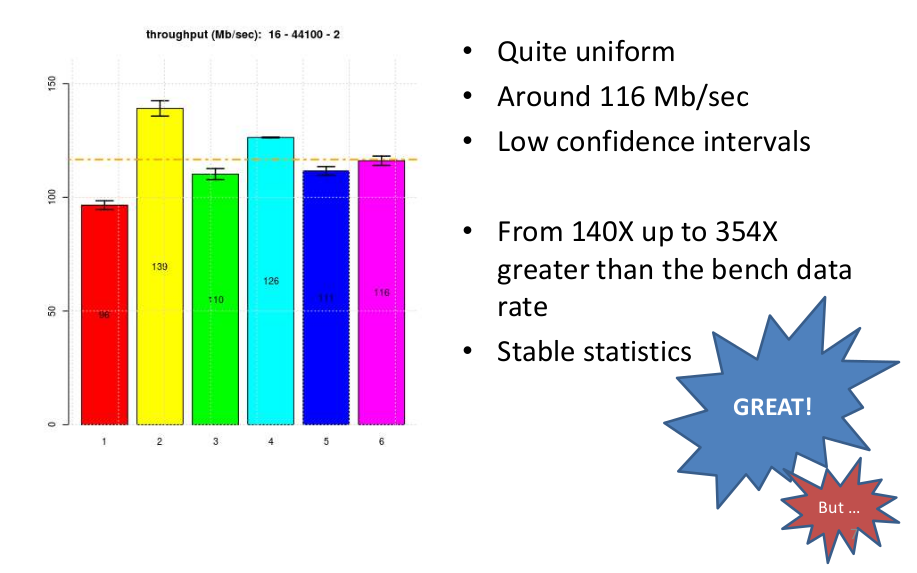
The benchmarking started by testing the baseline configuration (2-44-16, first line of the previous table) resulting on extremely good performance of our HW/SW architecture: quite uniform throughput of around 116 Mb/s, low variability and therefore low latency toward the output audio interface, stable statistics and large available performance margin to decode our typical audio files.
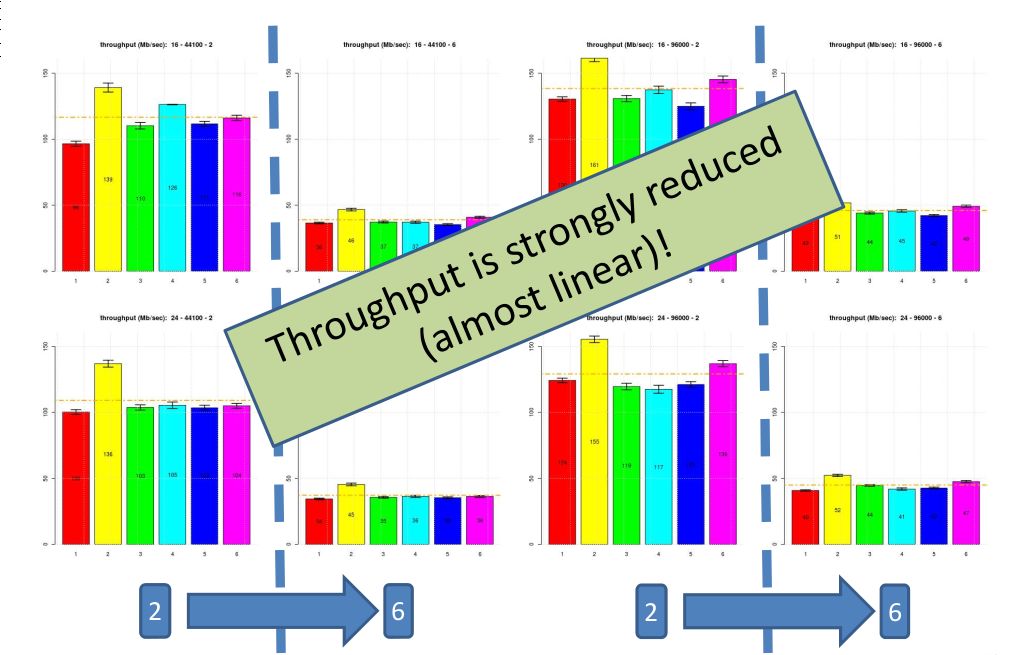
Then, we tested the whole set of configurations in order to investigate the effect of higher encoding precision, increased sample rate and number of channels to decode. Improving the encoding precision from 16 to 24 bps didn’t result on a relevant throughput reduction which was a good news to us since it meant that we could constantly provide high quality encoding without the need to add additional performance or to waste additional power consumption. Increasing the sampling rate produced a surprising increase of the throughput of the whole benchmark; after a detailed analysis this was essentially driven by the very effective memory architecture we adopted together with the optimization of buffers and code memory layouts we implemented.
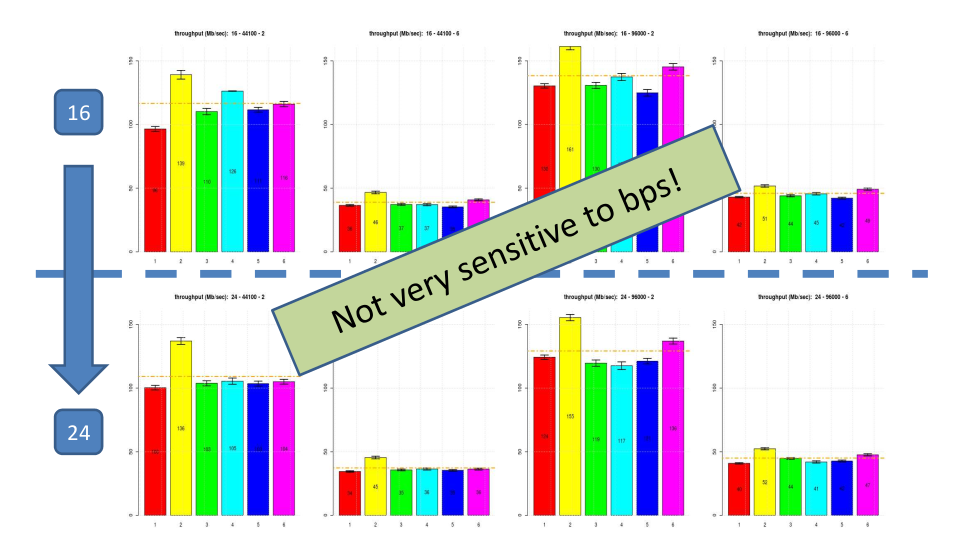
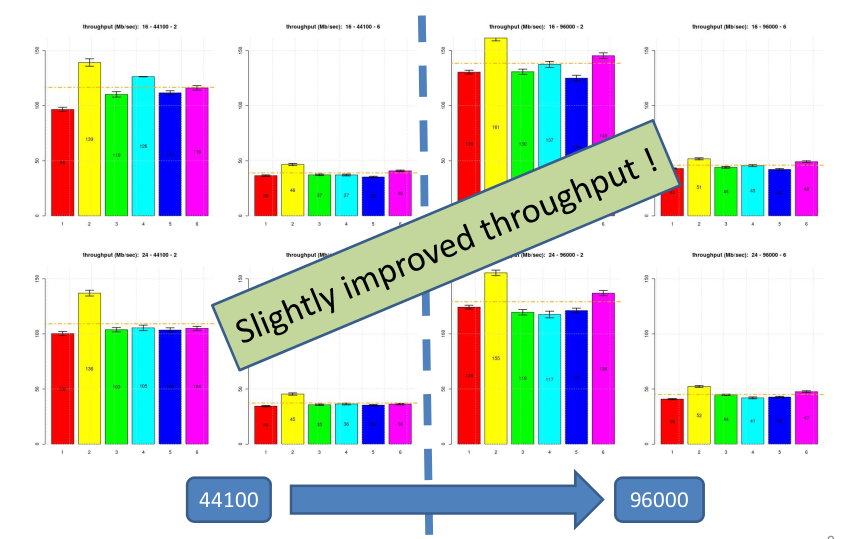
Instead, increasing the decoding channels from 2 to 6 had a very severe degradation of the throughput but this was expected, no surprise here, and it was almost linear. Overall, this was not a problem because we tested an ARM with a single core configuration but we could easily integrate a quad-core ARM and therefore to compensate for the throughput reduction.
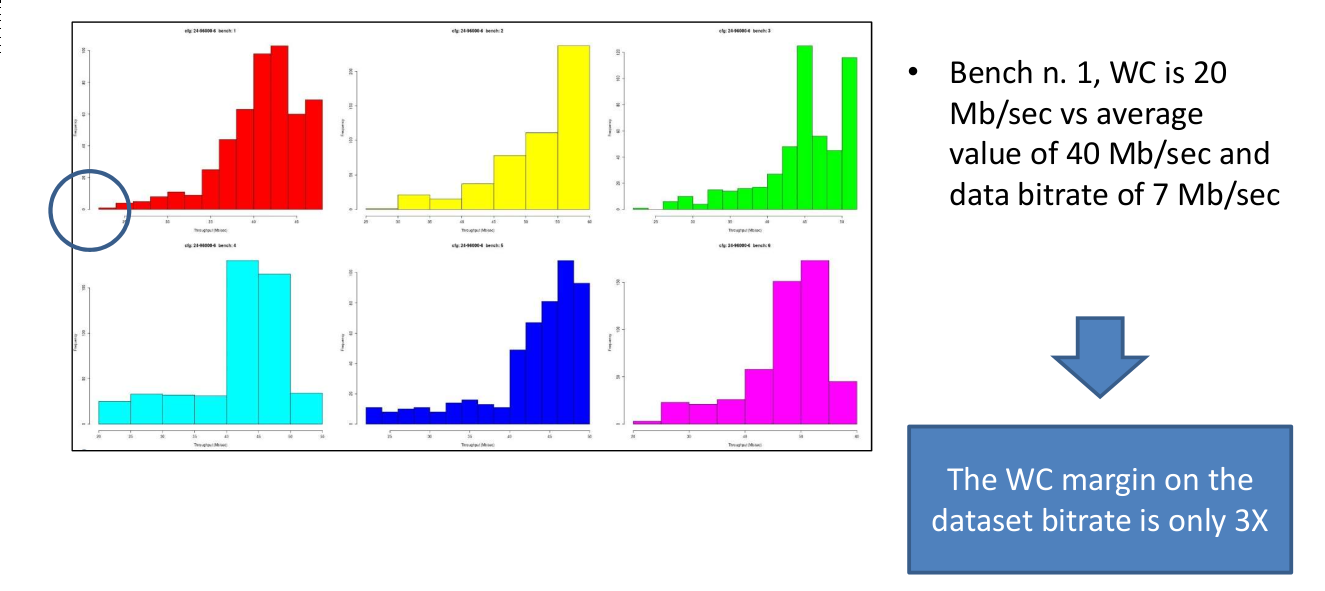
The second phase of the benchmarking was a detailed analysis of throughput distributions. All the tested configurations had a similar shape, a dominant distribution mass around the average with a long tail for the worst-case throughput. This is considered generally bad from a decoding perspective because it could result in unwanted latency or lag. However, given the large margin we had between the decoding bit rate and the data bit rate, this has not been a problem for most of the configurations. The highest demanding configuration (6-96-24) was the only exception, because a worst-case margin of 3X (see picture) was estimated not safe enough to decoded the audio and to do all the additional required computations. That’s why we opted for a final hardware architecture based on a dual core ARM.